
Comme vous le savez (ou pas) je forme aux techniques de mindmapping dans le cadre de la veille et de la gestion d’information depuis plus de 10 ans et je les utilise presque quotidiennement dans mes activités professionnelles et personnelles. Je vous propose donc une série d’articles dans laquelle je détaillerai le « process » que je mets en oeuvre pour traiter la documentation liée à mes veilles thématiques grâce à ces outils.
Pré-requis : il faut disposer d’un logiciel de mindmapping capable d’intégrer les dossiers et fichiers bureautiques de Windows. Mindmanager fait cela très bien mais est payant. En gratuit vous pouvez utiliser Freeplane qui s’en sort bien également même s’il est beaucoup moins ergonomique. Xmind, très bon par ailleurs, ne propose malheureusement pas cette fonctionnalité, un gros manque selon moi. Je détaillerai donc chacune des étapes pour les deux logiciels cités.
Dans les métiers de la veille et de l’analyse d’information, les documents ont rapidement tendance à s’accumuler et il faut mettre en place un système personnel de traitement de l’information si l’on souhaite en tirer la « substantifique moëlle ». J’ai donc développé, amélioré (et enseigné) depuis plusieurs années déjà un modèle de mindmap, que j’ai tout simplement baptisé « carte de travail », qui me permet à la fois de mieux gérer et de mieux exploiter (au sens d’aider à analyser) les contenus web découverts.
Voici donc le premier billet d’une série qui devrait en comporte six.
1ère étape : normaliser les articles découverts sur le web
Il ne s’agit pas d’une étape indispensable mais il est beaucoup plus facile de travailler avec les articles et contenus que vous aurez trouvé en ligne lorsqu’ils sont graphiquement normalisés. C’est à dire expurgés des bandeaux publicitaires et autres éléments nuisant à leur lecture. C’est encore mieux s’ils sont similaires dans leur présentation, un peu comme le sont par défaut les articles scientifiques.
Commençons donc par le commencement :
- C’est lundi matin, vous effectuez votre veille quotidienne et votre agrégateur de flux RSS favori vous remonte un article dont le titre attire votre attention (nota : vous pouvez aussi l’avoir découvert via une alerte Google, une newsletter à laquelle vous êtes abonné, un post sur Twitter, parce que vous visitez ce site tous les jours,…)
- Vous cliquez sur le lien afin d’aller sur la page d’origine de l’article car s’il est vraiment pertinent vous souhaiterez en enregistrer l’URL
- Avant ou après lecture de l’article vous ouvrez le bookmarklet ou l’extension Print Friendly (récupérable ici) qui va automatiquement nettoyer une bonne partie des éléments gênants comme vous pouvez les constater ci-dessous. Vous pouvez par ailleurs grâce à ce génial outil supprimer manuellement ce qui reste. Print Friendly va également normaliser la police de caractère des articles et conserver les images et illustrations ainsi que l’URL de l’article qu’il ajoute « en dur » dans sa version de la page. (Faites-le test, c’est magique :-))
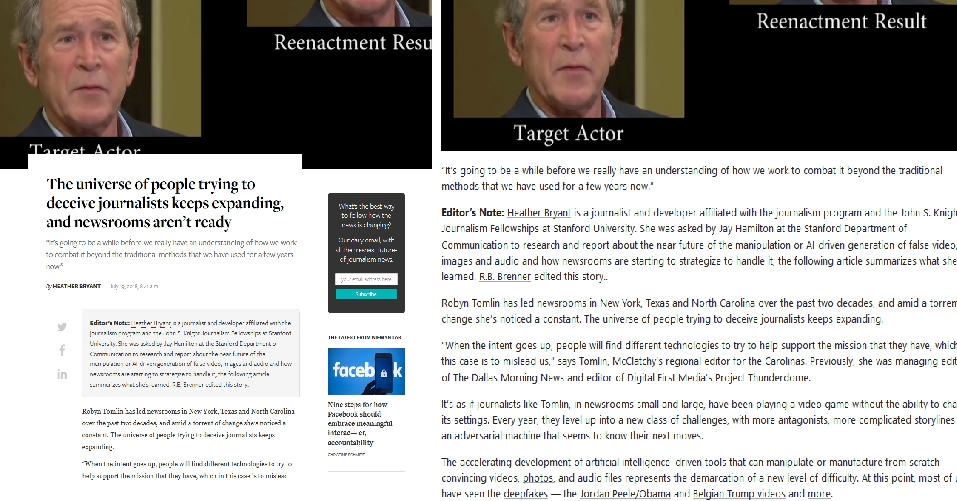
A gauche la page d’origine, à droite la version créée par Print Friendly - Vous allez maintenant enregistrer la version nettoyée de l’article au format PDF (option proposé par Print Friendly) dans un dossier thématique créé au préalable sur votre PC. Pour aller au bout de la logique normalisez aussi les titres de vos documents :
- Indiquez au début du titre une date à la mode anglaise, c’est à dire en l’inversant. Par exemple :
- 20181205_Nom_du_fichier
- vous pouvez aussi ajouter la source si vous le souhaitez
- 20181205_Nom_de_fichier-Source
- Indiquez au début du titre une date à la mode anglaise, c’est à dire en l’inversant. Par exemple :
Cette astuce vous permet ensuite de trier facilement vos documents par date ascendante ou descendante puisque les dates ainsi indiquées sont considérés par Windows (et autres OS) comme de simples chiffres : 20181205, 20181206, 20181209,…
Il arrive qu’occasionnellement Print Friendly ne parvienne pas à nettoyer une page, voir même à en récupérer le contenu. N’hésitez pas dans ce cas-là à utiliser un autre service du même type baptisé Readable et disponible sous forme de bookmarklet uniquement. A la différence du précédent, il ne permet pas le nettoyage manuel mais son nettoyage initial est généralement suffisant et, d’expérience, il arrive souvent à extraire un contenu quand Print Friendly reste bloqué. Lorsque Readable a été lancé sur une page il vous suffit de l’imprimer avec une imprimante PDF pour l’enregistrer ensuite dans votre dossier thématique.
Autre avantage lié à ces manipulations. Lorsque vous ferez une recherche « full-text » dans Windows (ou Mac, ou Linux), que vous utilisiez la recherche par défaut du système d’exploitation ou un moteur de recherche « desktop » (par exemple Copernic Desktop Search, DocFetcher ou Agent Ransack) vos recherches porteront uniquement sur le mots de l’article et pas sur ceux présents dans le reste de la page (publicités, suggestions d’autres articles, …). Vous gagnerez donc en pertinence tout en allégeant la consommation de mémoire de votre PC liée à l’indexation « full-text ».
Fin de la première étape. Oui je sais, je n’ai pas encore parlé de mindmapping mais chaque chose en son temps 🙂
Dans la seconde étape nous verrons comment préparer notre carte de travail.

Bonjour Christophe, Merci pour votre partage. J’ai découvert grâce à vous l’outil Print Friendly que je viens de tester et d’ajouter à mon navigateur. La fonction suppression de paragraphes est très intéressante. Un plus par rapport au super module « Reader » Firefox que j’utilise depuis plusieurs années. J’utilise régulièrement l’outil/méthode mindmap que je trouve formidable (si j’avais connu cela pendant ma scolarité…). En tant que formatrice et accompagnatrice VAE, j’en fais systématiquement la promotion. Bien cordialement.