Jusqu’à maintenant nous avions vu des fonctionnalités d’Inoreader intéressantes mais pas forcément différenciantes par rapport à d’autres agrégateurs. Ce n’est pas le cas de la fonctionnalité suivante dont j’ai un peu accéléré la rédaction du tutoriel puisque, toutes proportions gardées, elle peut nous permettre de mettre en œuvre le même type de filtrage que celui proposé par le presque défunt Yahoo! Pipes.
Attention, en version gratuite il n’est possible de créer qu’une seule règle (pas de limite en version).
Mise en oeuvre du filtrage par mots-clés
Nous partons du principe que vous disposez déjà de flux RSS dont certains que vous avez regroupés dans des dossiers thématiques (cf. la première partie).
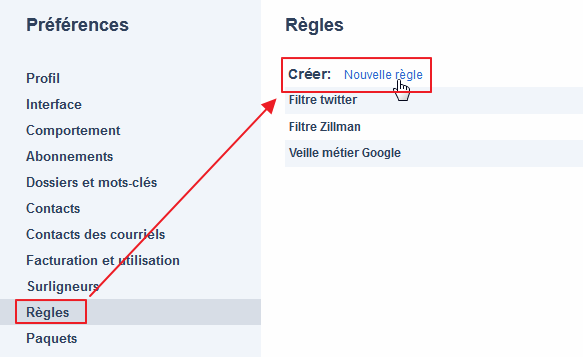
Pour accéder aux fonctionnalités de filtrage :
- Cliquez sur la roue crantée en haut à droite
- Choisissez « Préférences »
- Cliquez sur « Règles »
- Puis choisissez « Créer: Nouvelle règle »
Pour cet exemple je décide de filtrer une partie de mes flux RSS afin de faire remonter les items où apparaît l’expression « intelligence économique »
Choix du périmètre à surveiller
- Je donne un nom à la règle : « Filtre intelligence économique »
- Je choisis le périmètre des flux à filtrer. Il peut s’agir :
- de tous les flux présents dans mon agrégateur (par défaut)
- des flux présents dans un de mes dossiers thématiques que je choisi grâce au premier puis au second menu déroulant.
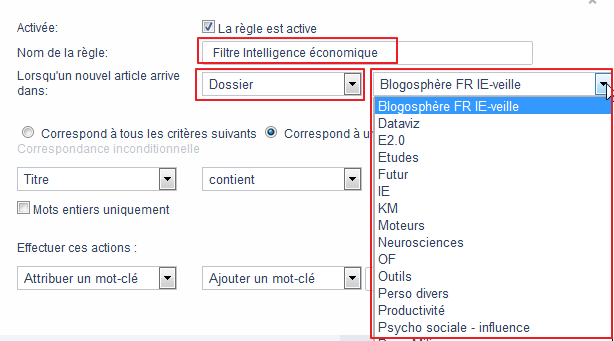
- d’un flux spécifique. Je choisis alors « Abonnement » dans le premier menu déroulant puis le flux en question dans le second menu déroulant.
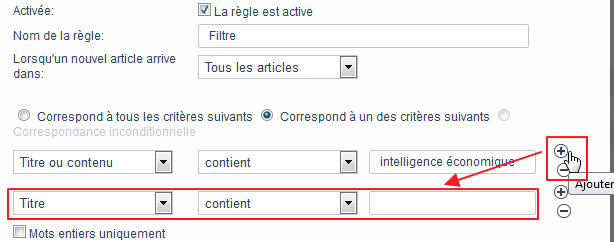
Choix des conditions de filtrage
C’est ensuite que les possibilités se complexifient.
- Je dois alors choisir si je souhaite rechercher avec tous les critères que je vais entrer ensuite ou seulement l’un d’eux. En logique booléenne c’est un choix entre ET et OU.
- Choisir l’élément de filtrage que vous allez privilégier. A savoir :
- Titre (de l’item)
- Contenu de l’item (soit le texte d’un article)
- Titre ou contenu
- Auteur (attention, il faut être sûr que ce champ sera renseigné par l’émetteur du flux)
- URL du flux : permet de filtrer les items provenant d’un flux grâce à l’URL de celui-ci
- URL sans domaine : permet de rechercher par mots-clés dans les URLS des items sans tenir compte du nom de domaine (v. l’explication sur le blog d’Inoreader)
- Contient des pièces jointes (pour filtrer les podcasts par exemple)
- Contient des images
- Contient une vidéo. Notez que lorsqu’un de ces 3 derniers choix est effectué, le champ « Contient » disparaît puisque l’on utilise plus de mots-clés pour créer un filtre
- Utilisez le menu déroulant du champ « Contient » pour préciser l’étendue des mots-clés que vous ajouterez dans le champ suivant :
- Contient / Ne contient pas : possibilité d’ajouter un mot précis ou une expression
- Est/n’est pas :
Ici j’ai eu beau chercher je ne vois pas ce qui différencie ces possibilités des deux précédentes. Peut-être la possibilité de forcer l’écriture exacte d’un mot pour qu’Inoreader ne recherche pas également une version accentuée ( ex : laisse/laissé). Même appel aux bonnes volontés donc.Merci à Sylvie Cocaud qui me propose une solution pour expliquer la différence entre les 2 dans les commentaires de ce billet. - Commence par/Se termine par : il s’agit des traditionnelles troncatures droites et gauche permettant par exemple de trouver tous les mots commençant par « chauss* » ou terminant par « *ette » dans un corpus, ici les items entrants.
- Correspond/Ne correspond pas à l’expression régulière : il est possible d’utiliser le puissant système d’expressions régulières, c’est à dire un ensemble de conventions syntaxiques reconnues par plusieurs langages de programmation. C’est assez complexe à manipuler mais extrêmement puissant. (voir l’article Wikipedia ,ces articles pour se former 1, 2 ainsi que cette application en ligne).
Vous pouvez ajouter des conditions supplémentaires et générer ainsi une requête multicritères en cliquant sur le bouton + pour ajouter une ligne.
Choix des actions mises en œuvre si les conditions sont requises
- Les articles correspondant à vos conditions de filtrage seront :
- Marqués comme lus
- Taggés (Attribuer un mot-clé).
- Indiquez alors le nom du tag en question dans la fenêtre de droite
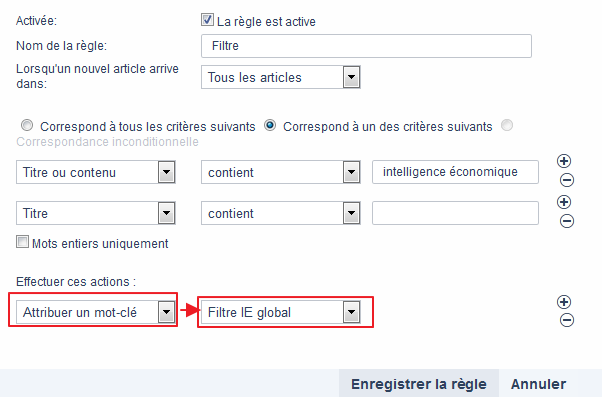
- Ce choix créera sur votre page principale de consultation des flux une entrée qui viendra se mêler aux dossiers (avec une icône différente) et récoltera au fil de l’eau tous les items répondant aux conditions mises en œuvre.

- Indiquez alors le nom du tag en question dans la fenêtre de droite
- Marquer : Correspond au clic sur l’étoile des favoris pour chaque article (v. partie I). Chaque item va donc automatiquement se classer dans la catégorie « Marqués »
- Publier : chaque item filtré est publié automatiquement dans « Ma chaîne » (v. partie II-2)
- Rediriger sur courriel : comme son nom l’indique. Une fois indiquée l’adresse email vous pourrez également ajouter un préfixe (mot-clé) dont chaque email envoyé via cette règle sera pourvu. Ce qui permettra de créer une règle de tri dans votre client email.
- Afficher une alerte sur le bureau: Attention ceci ne fonctionne que si Inoreader est ouvert dans votre navigateur.
- Rediriger vers des services de stockage/lecture différée (à condition d’avoir lié au préalable ces services à votre compte Inoreader) :
- Instapaper
- Readability
- Evernote
- Onenote
- Pousser les notifications mobiles. Les items seront alors reçus dans les applications mobiles d’Inoreader installées sur vos portables (Android, iOS)
Voici donc un système de filtrage des flux RSS puissant même si on y retrouvera pas toutes les possibilités offertes par Yahoo! Pipes ( par exemple le dédoublonnage sur le titre). Ce système est d’autant plus puissant qu’Inoreader a annoncé la semaine dernière la mise en place d’une chaîne dédiée chez IFTTT. Les possibilités de création de règles et les interactions avec des services tiers vont donc se démultiplier (l’équipe d’Inoreader en propose déjà une quarantaine) et j’aurai l’occasion d’en reparler. Si vous souhaitez un bon aperçu de ce qui est déjà possible je vous invite à consulter ce billet de Marjolein Hoekstra.
J’en profite pour indiquer que Marjolein propose également un carnet OneNote public dans lequel elle rassemble toute la documentation et les ressources en ligne qu’elle découvre sur cet agrégateur hors normes. Un must!
Bonjour Erwan,
Il est vrai que les REGEX permettent un filtrage ultra-fin mais je trouve qu’à moins d’avoir énormément de contenu à filtrer, l’investissement en temps d’apprentissage et de déploiement n’en vaut pas forcément la chandelle.
Avec le booléen proposé par le service et les possibilités de croisement de critères on peut déjà aller très loin.
Après c’est tjrs pareil, une question de calibrage en fonction des besoins. S’il est demandé à un veilleur de mettre en place une veille à l’internationale pour une grande entreprise à partir d’outils gratuits ou peu chers (çà arrive souvent en fait), il aura intérêt à s’investir dans les REGEX pour exploiter au mieux Inoreader).
Merci pour vos retours
Bonjour
Merci pour ces billets détaillés que je découvre sur ce super agrégateur. Avec un peu de retard donc, je propose cette réponse à votre question concernant la spécificité du test « Est/n’est pas » par rapport à « contient/ne contient pas » : le premier retrouve l’expression exacte, par exemple :
« Est = Data » ne retrouve pas « Data Curation Network » alors que « contient = Data » le retrouve
Merci beaucoup pour cette information. Je voulais pousser mes tests pour essayer de comprendre et puis j’ai oublié de le faire 🙂
Je vais faire la modif dans l’article.