En ce presque début d’année (que je vous souhaite excellente), je reprends ma série sur la veille Quick & dirty avec un petit tour par Bing.
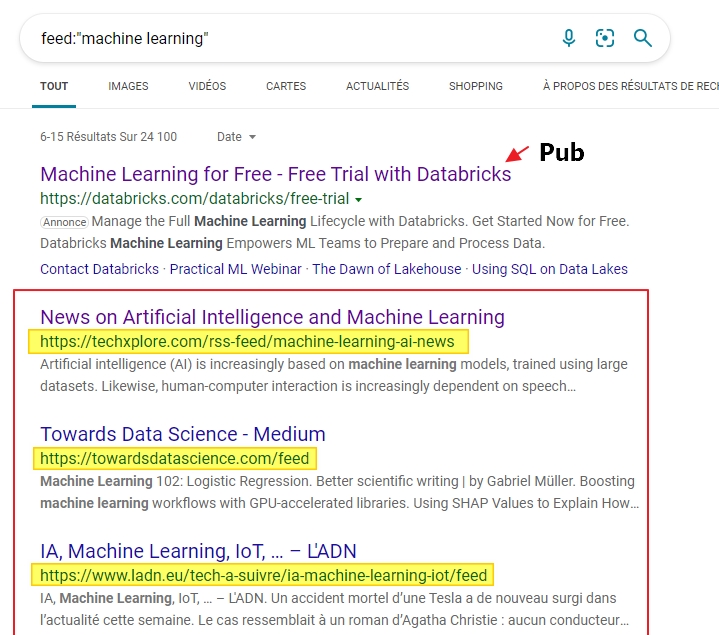
Comme vous le savez si vous lisez ce blog, Bing dispose d’un opérateur de recherche très intéressant pour les veilleurs puisqu’il permet de rechercher des flux rss thématique par mots-clés thématiques. Il s’agit de l’opérateur « feed: » que l’on va utiliser ainsi dans une requête :feed:"machine learning"
Le résultat :
A l’instar de ce que nous avons fait dans le précédent article, nous allons utiliser un outil de scraping très simple pour récupérer ces résultats. Instant data scraping n’ayant pas donné satisfaction dans ce cas, j’ai utilisé un autre outil pratique et facile à mettre en œuvre, le service Data Miner dans sa version gratuite, qui ne nécessite que la création d’un compte et l’ajout d’une extension à son navigateur (Chrome).
Pour récupérer les flux RSS proposés comme résultats dans Bing il faut à partir de la page de résultats :
- Cliquez sur le bouton de l’extension dans son navigateur
- Pas besoin de créer une « recette » (recipe) car l’outil en propose qui ont été créées par d’autres utilisateurs. On utilisera ici la recette intitulée {Bing – Title, Summary and URL scrape}
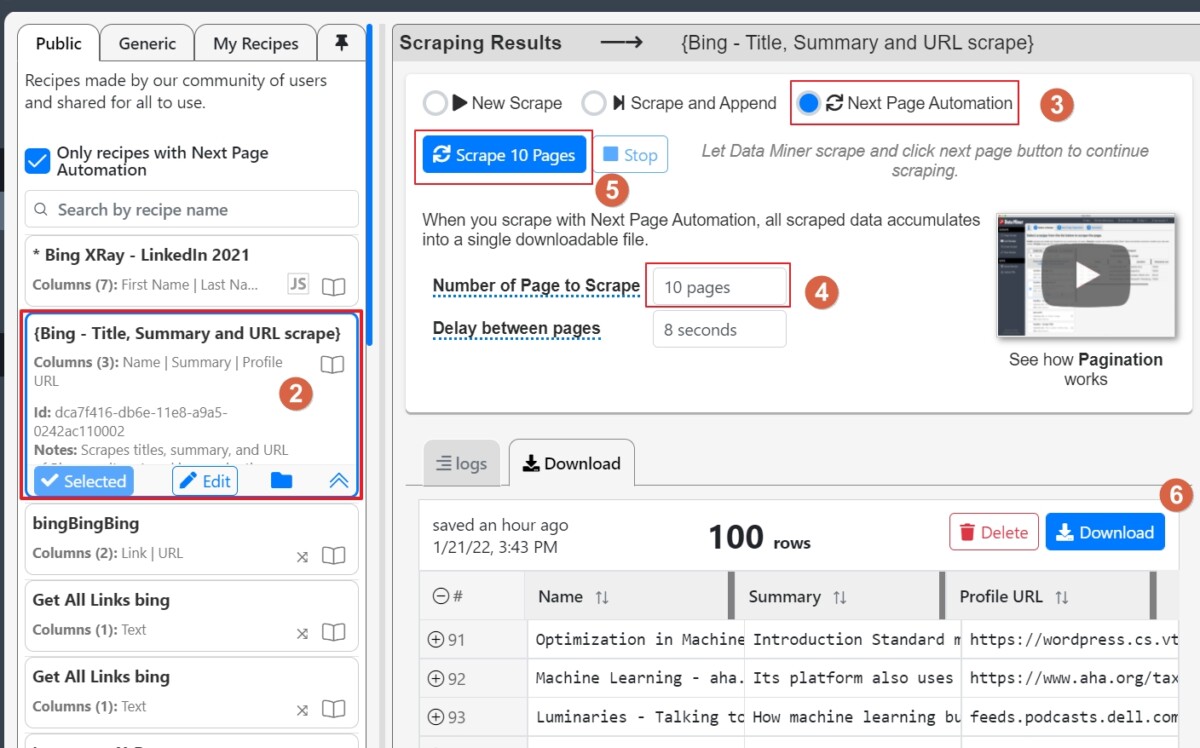
- Sélectionnez « Next Page Automation » afin de pouvoir récupérer les résultats des pages 2,3,4, etc sans avoir à recliquer.
- Choisissez le nombre de pages de résultats à scraper
- Cliquez sur le bouton bleu « Scrape x pages ». Le crawling démarre et s’arrêtera tout seul à la fin de la 10ème page (dans cet exemple)
- Cliquez ensuite sur le bouton « Download » et choisissez l’option « Excel file »
- Ouvrez le fichier dans Excel et copiez la colonne C dans laquelle se trouvent les flux récupérés
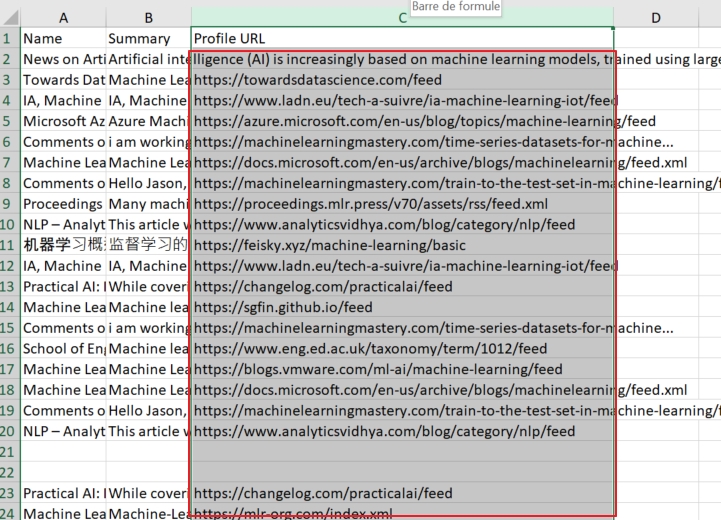
- Collez-les dans le service OPML Generator, déjà utilisé à plusieurs reprises dans cette série d’articles
- Sauvegardez le fichier OPML sur votre disque dur
- Puis importez-le dans votre agrégateur de flux RSS
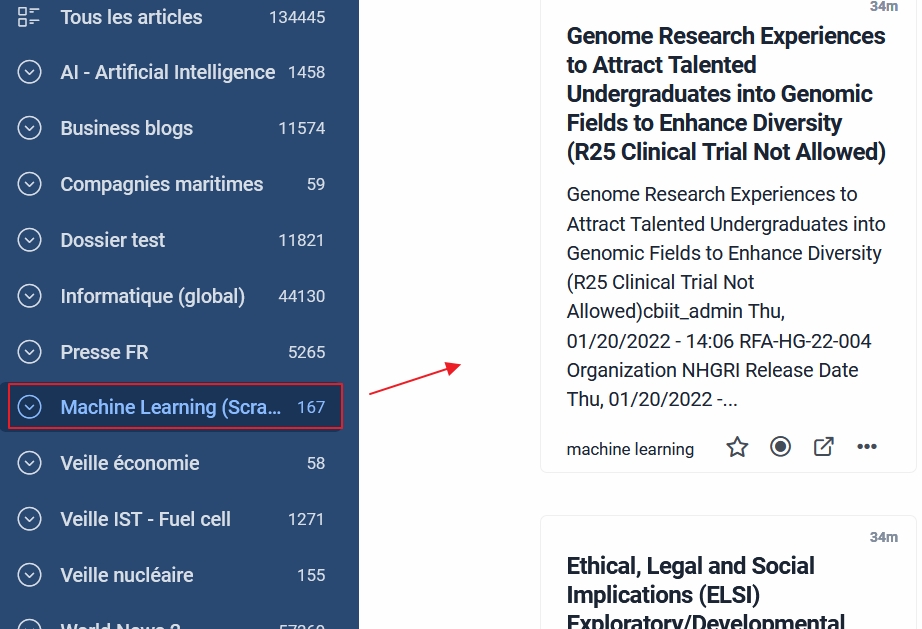
- Vous venez de récupérer 100 flux RSS traitant de machine learning

