Dans la première partie de cette série d’articles nous avions vu comment récupérer des centaines de flux RSS d’actualité en quelques clics grâce à l’Atlas des flux RSS. Dans cette seconde partie nous allons voir comment récupérer des paquets de sources thématiques créés par les utilisateurs d’Inoreader. Cet article s’adresse donc plutôt à eux, même si les autres pourront toujours créer un compte Inoreader gratuit pour cela et exporter ensuite les flux récupérés au format OPML (cf. ci-dessous).
Lors de son lancement en 2014 suite à la suppression de Google Reader, Inoreader avait repris l’idée des « bundles », à savoir des paquets de flux RSS thématiques que chaque utilisateur peut créer et partager avec d’autres. S’il est toujours possible d’en créer, la fonctionnalité permettant de les rechercher dans l’interface d’Inoreader a mystérieusement disparu. Il va donc falloir faire appel à Google en utilisant l’indispensable opérateur « site: ». Il faut également connaître la structure des URL des bundles d’Inoreader. Une fois muni de cette information il suffit de lancer la requête suivante en utilisant bien sûr vos propres mots-clés thématiques. Par exemple :
site:www.inoreader.com/bundle/* "artificial intelligence" OR "intelligence artificielle"
Un conseil, ne cherchez pas ici à faire des requêtes fines, le but est de collecter rapidement un grand nombre de sources susceptibles de couvrir les sujets qui vous intéressent. Ce n’est que dans un second temps que vous filtrerez les contenus remontés grâce aux différents outils de filtrage par mots-clés proposés par Inoreader.
Ici les résultats sont nombreux puisque nous obtenons 19 bundles :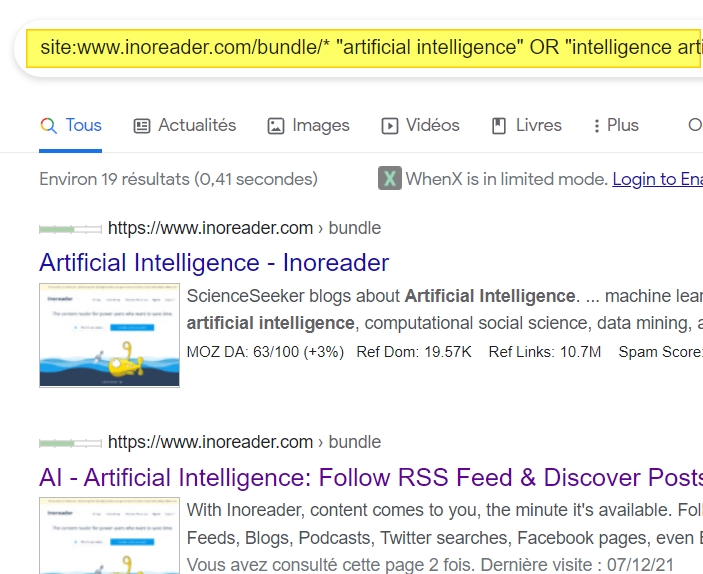
Pour les intégrer à Inoreader il faut :
- avoir ouvert Inoreader dans un autre onglet de votre navigateur
- cliquer sur les résultats intéressants proposés par Google. Vous obtenez alors la page suivante dans Inoreader :
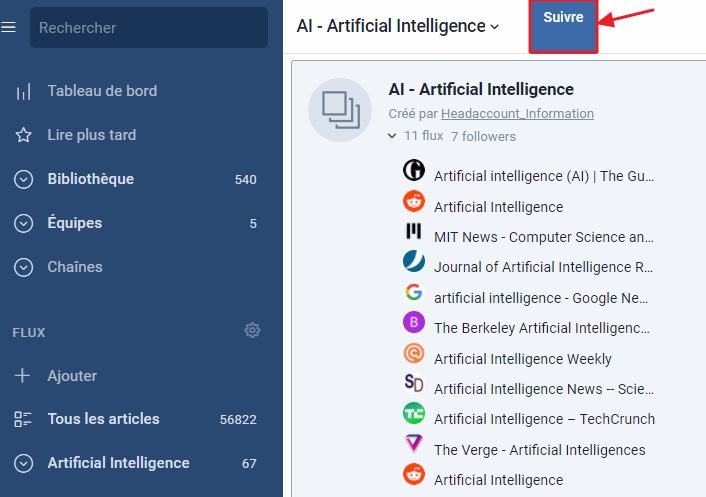
- cliquer sur le bouton « Suivre » pour s’abonner.
- Le bundle est créé dans votre compte Inoreader en tant que nouveau dossier.
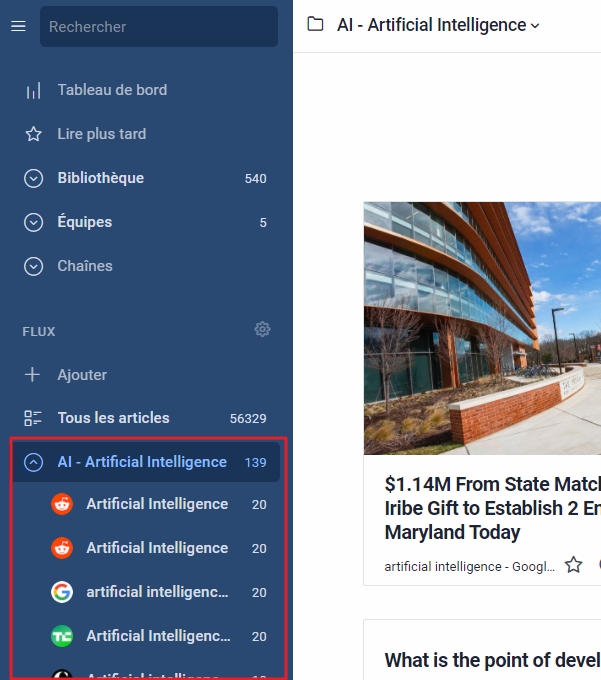
Ceux qui n’utilisent pas Inoreader et ont créé un compte gratuit dans le seul but de récupérer les bundles peuvent le faire rapidement en cliquant sur les trois petits point à droite, en choisissant « Télécharger le fichier OPML » puis en l’important dans leur agrégateur.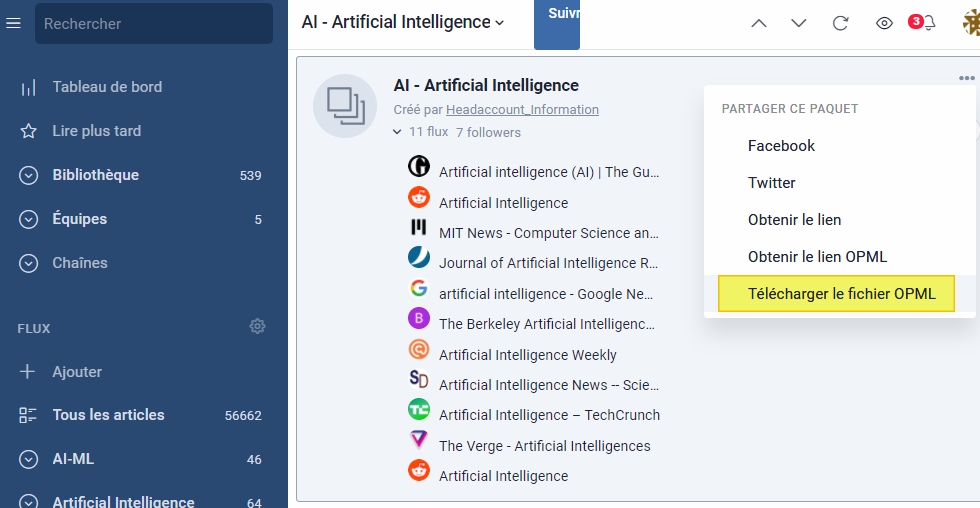
Avec cette technique et toujours dans l’idée d’aller vite ce sont encore des centaines de flux RSS auxquels vous pouvez vous abonner en quelques clics.


1 commentaire