Un veilleur sachant veiller est aussi un analyste. Bien sûr il ne sera jamais aussi pointu que les experts des domaines pour lesquels il récolte l’information mais avec le temps il développera, heureusement, une expertise propre qui lui permettra d’être de plus en plus pertinent sur les informations captées et de plus en plus capable de percevoir les inflexions significatives de son secteur d’activités. Après tout n’oublions jamais que sélectionner une info spécifique parmi un flux d’infos thématique c’est déjà mettre en oeuvre sa capacité d’analyse.
Les techniques d’analyse sont innombrables comme nous l’avions vu avec les étudiants de l’ICOMTEC de Poitiers en rédigeant le Livre blanc des méthodes d’analyse appliquées à l’intelligence économique. Parmi elles il y en a une à laquelle je me frotte régulièrement qui est l’analyse automatique de texte ou text mining. Je ne prétends pas être un spécialiste du sujet mais, ayant pas mal joué avec des solutions comme Tropes ou le défunt Umap de Trivium j’ai vite vu qu’on pouvait « faire parler » des textes sans trop de difficultés techniques à condition de comprendre un minimum ce que l’on fait.
Voyant tools est justement un de ces outils plutôt simple à mettre en oeuvre (plus que les deux précités) et permettant d’analyser des textes ou des corpus de texte. Ce projet open-source est dirigé par les universitaires canadiens Stéfan Sinclair et Geoffrey Rockwell et le code est disponible sur GitHub. Voyant Tools est accessible à l’adresse http://voyant-tools.org/ mais j’ai choisi d’utiliser pour ce test la version bêta accessible ici après tout autant gagner du temps. Attention l’accès initial à la page d’accueil est parfois très lent.
C’est dès la page d’accueil que vous pourrez ajouter des contenus à analyser. Il est possible d’ajouter :
- des URL de textes en ligne, y compris des URL multiples en changeant de lignes
- un texte, par copier-coller
- un corpus de documents présents sur votre poste qui sera alors chargé sur la plateforme
J’ai choisi de faire simple pour commencer en utilisant un seul texte, les voeux présidentiels pour 2016 que j’ai copié-collé du site de l’Elysée.
Le résultat initial est celui-ci :
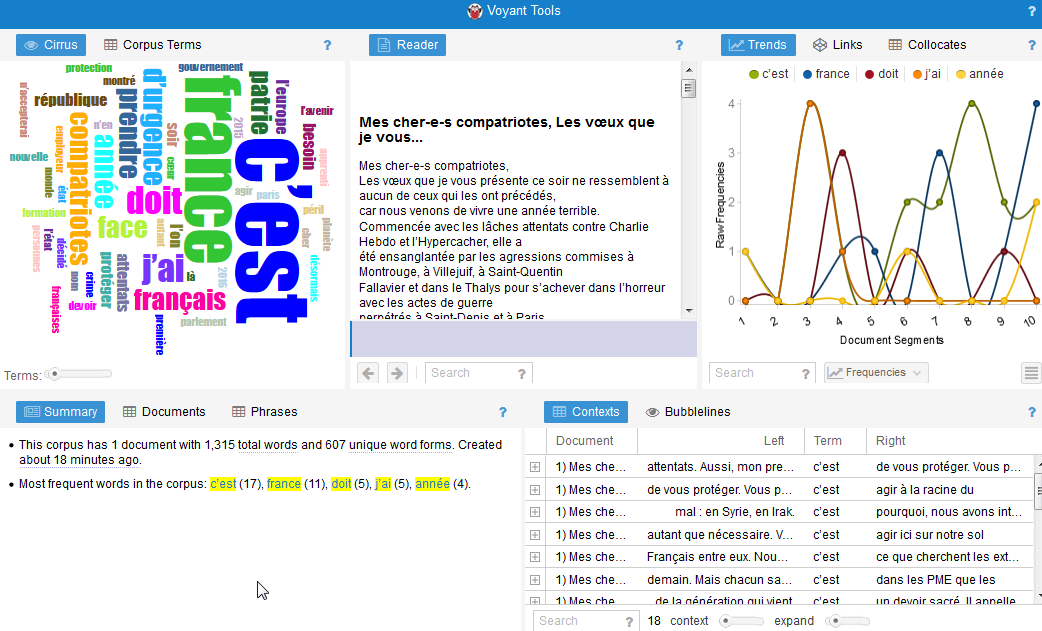
On constate que la page de résultats est divisée en cinq blocs. On y trouve par défaut de gauche à droite et de haut en bas :
- un nuage de tags (Cirrus)
- le texte analysé
- les courbes de fréquence d’apparition des mots-clés les plus présents dans le texte
- le nombre de documents analysés (ici un seul), de mots dans le(s) document(s) et les mots-clés les plus présents
- les mots-clés dans leur contexte, c’est à dire dans la phrase où ils sont cités
Prenons maintenant chaque bloc un par un :
- Nuage de tags :
- ce bloc est pour l’instant pollué par des mots-clés indésirables comme « c’est » qui est par ailleurs le mot-clé le plus cité dans ce texte. Pour faire disparaître ces mots génants nous cliquons sur « Define options for this tool ».
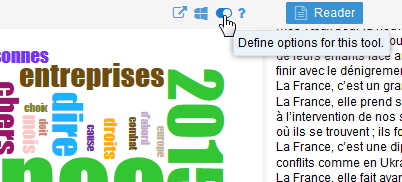 Une liste de « stop words » dans plusieurs langues apparaît dans un menu déroulant.
Une liste de « stop words » dans plusieurs langues apparaît dans un menu déroulant. 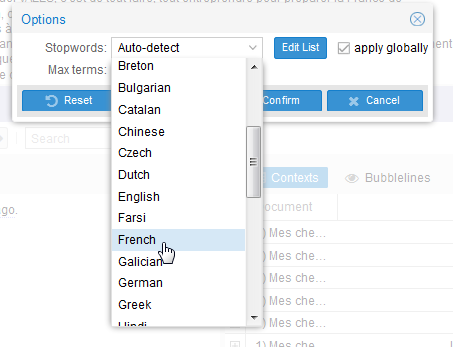 Nous choisissons ici le français bien sûr et conservons le « apply globally » afin que les autres modules soient également débarassés des mots génants. C’est mieux mais le « C’est » reste toujours majoritaire. Nous retournons dans la liste et choisissons de l’éditer pour y ajouter le « c' » et le « c’est ». Bon malheureusement çà ne fonctionne pas et nous resterons donc avec ce mot en occurence la plus citée dans le texte 🙁 Probablement un problème avec l’apostrophe car çà marche bien avec d’autres mots. Sinon on voit clairement ici qu’hormis le mot « France » le discours met en avant les termes « d’urgence » (4 occurences), « face » (4), « français »/ »compatriotes » (8) et le grand retour de « patrie » cité 4 fois contre aucune l’an dernier. Le terme « confiance » cité 6 fois l’an dernier n’est plus présent qu’une seule, idem pour « chômage » cité une fois contre trois. Notons aussi l’utilisation élevée de tournures personnelles avec « je » (11) et « j’ai » (5) qui rappellent un peu le « moi président ».
Nous choisissons ici le français bien sûr et conservons le « apply globally » afin que les autres modules soient également débarassés des mots génants. C’est mieux mais le « C’est » reste toujours majoritaire. Nous retournons dans la liste et choisissons de l’éditer pour y ajouter le « c' » et le « c’est ». Bon malheureusement çà ne fonctionne pas et nous resterons donc avec ce mot en occurence la plus citée dans le texte 🙁 Probablement un problème avec l’apostrophe car çà marche bien avec d’autres mots. Sinon on voit clairement ici qu’hormis le mot « France » le discours met en avant les termes « d’urgence » (4 occurences), « face » (4), « français »/ »compatriotes » (8) et le grand retour de « patrie » cité 4 fois contre aucune l’an dernier. Le terme « confiance » cité 6 fois l’an dernier n’est plus présent qu’une seule, idem pour « chômage » cité une fois contre trois. Notons aussi l’utilisation élevée de tournures personnelles avec « je » (11) et « j’ai » (5) qui rappellent un peu le « moi président ». - En cliquant sur l’onglet « Corpus term » on fait apparaître la version liste du nuage de tags (Cirrus). Les en-têtes colonnes sont cliquables afin de modifier le mode de classement proposé (ceci sur l’ensemble des tableaux proposés dans Voyant-Tools).
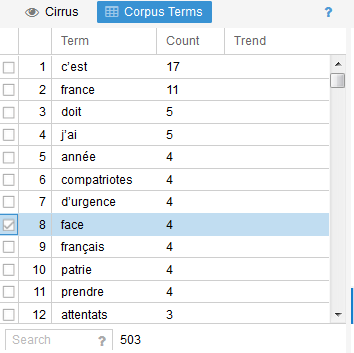
- Gros avantage de Voyant-Tools, les différents blocs de la page se « recalculent » en fonction des mots-clés que vous sélectionnez dans le nuage ou la liste. Vous permettant d’avoir dans une seule fenêtre différents traitements de celui-ci comme nous allons le voir en cliquant maintenant sur le mot « Patrie ».
- ce bloc est pour l’instant pollué par des mots-clés indésirables comme « c’est » qui est par ailleurs le mot-clé le plus cité dans ce texte. Pour faire disparaître ces mots génants nous cliquons sur « Define options for this tool ».
- Reader :
- c’est bien sûr l’espace où l’on accède au texte brut. On peut y naviguer grâce au petit histograme de fréquence accessible juste en dessous du texte et qui nous indique à quels endroits le mot-clé qui nous intéresse est cité. Ici les 4 occurences sont regroupées en fin de texte et surlignées automatiquement:
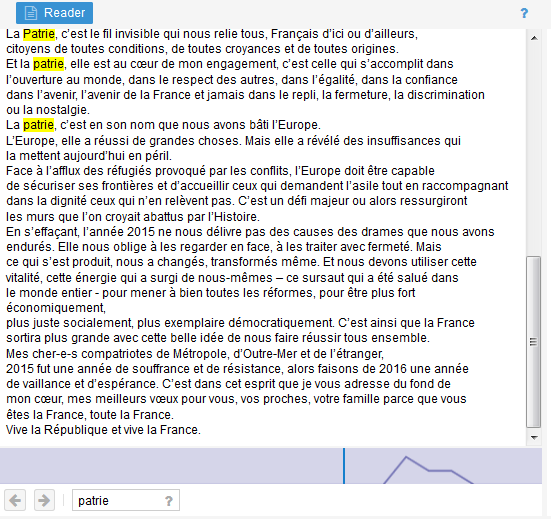
- Il est aussi possible de rechercher un mot-clé dans le texte grâce à la boîte de recherche prévue à cet effet. Elle est présente sous chaque bloc et le possibilités de requêtes sont avancées (troncatures, proximité, OR sous forme de pipe,…)
- Enfin, en double-cliquant sur un mot dans le texte, il devient mot sélectionné pour l’ensemble des blocs.
- c’est bien sûr l’espace où l’on accède au texte brut. On peut y naviguer grâce au petit histograme de fréquence accessible juste en dessous du texte et qui nous indique à quels endroits le mot-clé qui nous intéresse est cité. Ici les 4 occurences sont regroupées en fin de texte et surlignées automatiquement:
- le troisième bloc par défaut est Trends mais on y trouve également un onglet Links et un autre Collocates :
- Trends : il s’agit du même histograme que ci-dessus mais plus facile à exploiter. Un clic sur une occurence fait défiler le texte du reader au bon endroit. Il est possible de sélectionner plusieurs mots à partir du « Corpus term » afin de comparer leurs fréquences et lieux d’apparition dans le texte/corpus de documents.
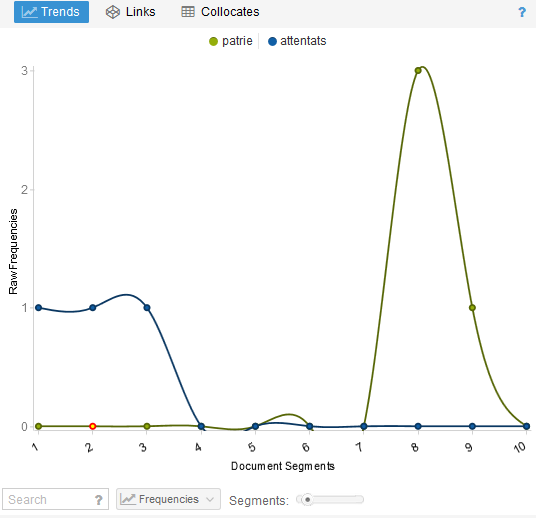 Par exemple en sélectionnant « attentats » et « patrie » on pourrait déduire du graphique l’utilisation dans ce discours d’un ressort dramatique classique, parler d’abord de ce qui effraye puis terminer en utilisant des mots qui rassurent et en recherchant l’unité : faire face en tant que patrie et pour la défendre.
Par exemple en sélectionnant « attentats » et « patrie » on pourrait déduire du graphique l’utilisation dans ce discours d’un ressort dramatique classique, parler d’abord de ce qui effraye puis terminer en utilisant des mots qui rassurent et en recherchant l’unité : faire face en tant que patrie et pour la défendre. - Links : il s’agit d’un cluster représentant les occurences les plus citées dans son corpus et les mots-clés (co-occurences) auxquelles elles sont le plus souvent associées.

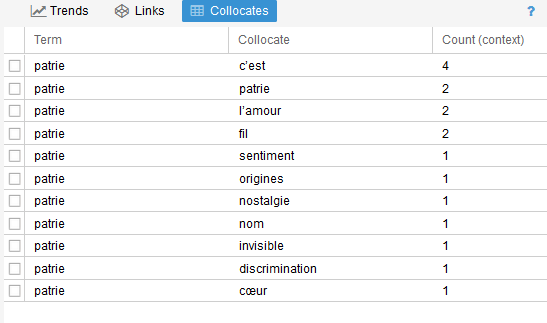
- Collocates : liste des mots-clés les plus souvent citées avec l’occurence sélectionnée (proximité).
- Trends : il s’agit du même histograme que ci-dessus mais plus facile à exploiter. Un clic sur une occurence fait défiler le texte du reader au bon endroit. Il est possible de sélectionner plusieurs mots à partir du « Corpus term » afin de comparer leurs fréquences et lieux d’apparition dans le texte/corpus de documents.
- Le bloc par défaut est Summary et il est associé à deux autres onglets, Documents et Phrases :
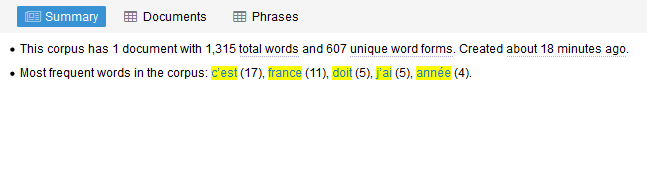
- Summary : vous donne des infos factuelles sur le texte/corpus étudié : nombre de mots, nombre de documents, mots les plus fréquents
- Documents : liste de manière détaillée l’ensemble des documents du corpus étudié
- Phrases : vous indique si le mot sélectionné est utilisé dans des schémas répétitifs. Ici par exemple le mot « face » et utilisé trois fois sur quatre en « face à ».
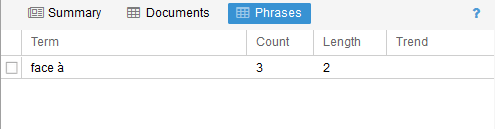
- Summary : vous donne des infos factuelles sur le texte/corpus étudié : nombre de mots, nombre de documents, mots les plus fréquents
- Le dernier bloc par défaut est Contexts associé à l’onglet Bubblelines
- Contexts : on va trouver ici le mot sélectionné dans les phrases où il est utilisé avec le rappel du document auquel il est rattaché lorsqu’il s’agit d’un corpus.
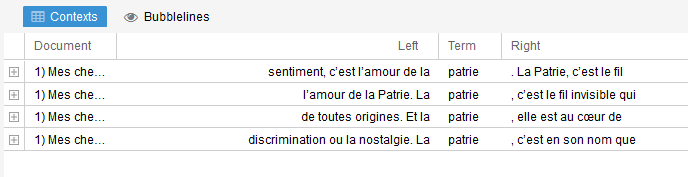
- Bubblelines : affiche la distribution des occurences les plus fortes dans le texte

- Contexts : on va trouver ici le mot sélectionné dans les phrases où il est utilisé avec le rappel du document auquel il est rattaché lorsqu’il s’agit d’un corpus.
Nous avons maintenant fait le tour de la partie émergée de l’iceberg… Parce qu’après cela il y a tous les blocs-outils que vous pouvez ajouter pour multiplier les types d’analyse de votre texte.
Pour cela rendez-vous dans le coin en haut à droite d’un bloc et cliquez sur ce qui resemble au logo Windows. Un menu apparaît alors qui vous propose de remplacer l’outil actuellement visible par un autre à choisir dans un menu déroulant à deux niveaux :
Un menu apparaît alors qui vous propose de remplacer l’outil actuellement visible par un autre à choisir dans un menu déroulant à deux niveaux :
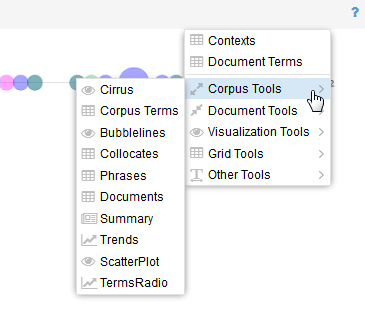
L’ensemble de ces outils est listé et détaillé sur cette page de la partie Aide du site, très complète par ailleurs.
Sachez également qu’il est possible d' »embarquer » une vue d’un outil de la même manière que l’on embarque une vidéo Youtube sur son blog. Pour cela il faut cliquer en haut à droite de l’outil sur la petite flèche partant vers le haut. On choisit en suite d’exporter une image (visualization) ou une vue dynamique (view). Dans ce cas l’export peut être un snippet HTML à ajouter à une page web ou une référence bibliographique de la vue en question (ils ne sont pas universitaires pour rien!).
Notez qu’en vous positionnant en haut à droite de la page principale, dans la bande bleue, vous retrouvez cette possibilité avec l’export ici de toute la page et des ses blocs.
Pour conclure il me semble que Voyant-tools est une plateforme très aboutie et très puissante pour analyser des textes et des corpus de textes. Bien sûr je ne suis pas expert de ce domaine et j’invite ceux-ci à me contredire si nécessaire. Dans tous les cas elle s’avèrera déjà très suffisante pour analyser des discours et interventions de PDG d’entreprises concurrentes. On pourra bien sûr faire de même avec les propos de sa propre direction pour voir, par exemple, si les discours et interviews de ses membres pris comme corpus d’étude n’en disent finalement pas trop sur les objectifs de l’organisation.
Au rayon des reproches il y a bien sûr le fait que les stop-words fonctionnent mal pour le français, après test, ce bug existe également sur la version officiel de Voyant-Tools, il y a donc bien un problème et c’est dommage. Si les créateurs de la plateforme lisent cet article…
Par ailleurs on peut constater parfois une latence assez forte lorsqu’on sélectionne un mot-clé avant qu’il ne soit identifié et traité dans les différents blocs. J’espère que ce n’est qu’un souci lié au fait qu’il s’agit du serveur bêta. Ce serait vraiment dommage qu’un si bel outil soit limité par des questions de puissance de serveur.
Amusez-vous bien!
Outil qui a l’air très intéressant ! Merci Christophe pour tes billets toujours de qualité 🙂
Je vais m’empresser de tester !
Moi itou.
C’est toujours aussi chaud sur outils froids
Merci
Superbe ! Merci pour cet article. J’ai enfin trouvé « Voyant Tools », et ça marche !
super merci Christophe
Je viens de tester et après un premier essaie je trouve l’outille SUPER!
Facile à utiliser en ligne !
Merci Christophe !
Merci beaucoup. Et.bien je m’en vais essayer cet outil.